[ 목차 ]
1. SQL 기본 명령어
2. 연산자
3. 그룹함수
4. 집합연산자
5. 하위질의 (SubQuery)
6. 테이블 생성
7. VIEW
8. SYNONYM
# hr 계정의 테이블 구조 및 항목
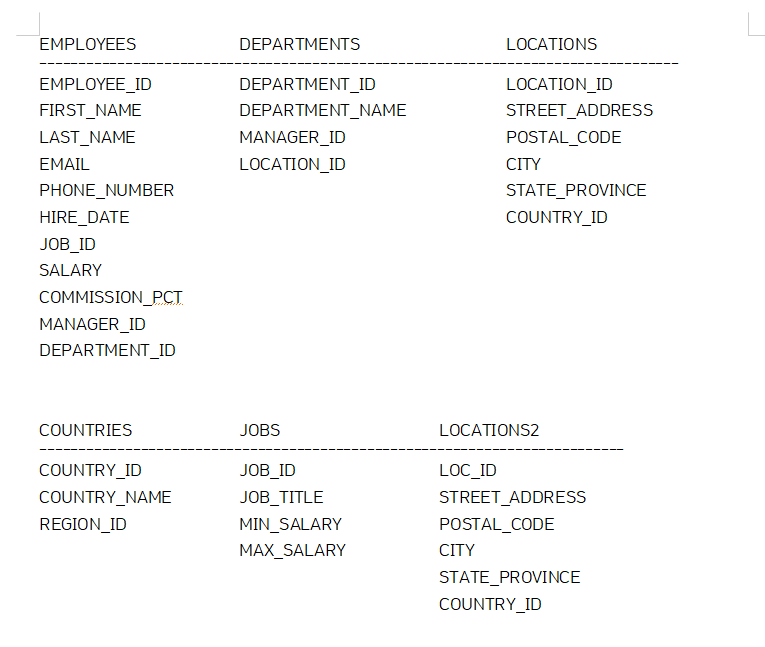
# 테이블 구성 확인 명령어
desc employees;
이름 널? 유형
-------------- -------- ------------
EMPLOYEE_ID NOT NULL NUMBER(6)
FIRST_NAME VARCHAR2(20)
LAST_NAME NOT NULL VARCHAR2(25)
EMAIL NOT NULL VARCHAR2(25)
PHONE_NUMBER VARCHAR2(20)
HIRE_DATE NOT NULL DATE
JOB_ID NOT NULL VARCHAR2(10)
SALARY NUMBER(8,2)
COMMISSION_PCT NUMBER(2,2)
MANAGER_ID NUMBER(6)
DEPARTMENT_ID NUMBER(4)
★ 1. SQL 기본 명령어
1. 데이타 조작어(DML : Data Manipulation Language)
: insert, update, delete, merge
2. 데이타 정의어(DDL : Data Definition Language)
: create, alter, drop, rename, truncate
3. 데이타검색
: select
4. 트랜젝션제어
: commit, rollback, savepoint
5. 데이타 제어어(DCL : Data Control Language)
: grant, revoke
# select
select : 출력문
[형식]
select [distinct] [컬럼1,컬럼2,.....][as 별명][ || 연산자][*]
from 테이블명
[where 조건절]
# ex1) employees테이블의 모든 사원의 사원번호, 이름(last_name), 급여 검색
select employee_id, last_name, salary from employees;ex2) 컬럼명 지정하기(as는 생략가능)
employees테이블의 모든 사원의 사원번호, 이름(last_name), 급여 검색
조건) title 사원번호, 이름 ,급여로 출력할것
select employee_id 사원번호 , last_name as 이름, salary as "급 여"
from employees;
-- 컬럼명에 공백을 넣을때는 "" 쌍따옴표 이용ex3) employee테이블에서 사원번호, 이름, 연봉을 구하시오
조건1) 연봉 = 급여 * 12
조건2) 제목을 사원번호, 이름, 연봉으로 출력
select employee_id as 사원번호 , last_name as "이 름", salary*12 as "연 봉"
from employees;ex4) 연결연산자( || ) : 컬럼을 연결해서 출력
frist_name과 last_name을 연결해서 출력하시오
select first_name||' '||last_name as "이 름" from employees;
# distinct
distinct : 중복제거
* : 모든
조건절 : and, or, like, in, between and, is null, is not null
ex5) employees 테이블에서 부서ID를 각각 하나씩만 출력하시오
select distinct department_id from employees;ex6) 10번부서 또는 90번부서 사원들의 이름, 입사일, 부서ID를 출력하시오
select last_name, hire_date, department_id
from employees
where department_id=10 or department_id=90;ex7) 급여가 2500이상 3500미만인 사원의 이름(last), 입사일, 급여를 검색하시오
select last_name, hire_date, salary
from employees
where salary>=2500 and salary<3500;
# 급여가2500이하 이거나3000이상이면서90번 부서인 사원의 이름,급여,부서ID를 출력하시오.
조건1) 제목은 사원명, 월 급, 부서코드로 하시오
조건2) 급여 앞에 $를 붙이시오
조건3) 사원명은 first_name과 last_name을 연결해서 출력하시오
ex8) 'King'사원의 모든 컬럼을 표시하시오
select * from employees where last_name='King';
--문자열을 검색할 때는 대, 소문자를 구분한다.
select * from employees where lower(last_name)='king';
-- 출력되는 last_name 컬럼을 모두 소문자로 변경 후 일치하는 항목 찾기# like : 문자를 포함
- '%d' - d로 끝나는
- 'a%' - a로 시작하는
- '%test% - test가 포함되어있는
- '_a%' - 두번째 글자가 a로 시작하고 나머지는 무시
- '__a%' - 세번째 글자가 a로 시작하고 나머지는 무시
ex9) 업무ID에 MAN이 포함되어있는 사원들의 이름, 업무ID, 부서ID를 출력하시오
select last_name, job_id, department_id
from employees
where job_id like '%MAN%';ex10) 업무ID가 IT로 시작하는 사원들의 이름, 업무ID, 부서ID를 출력하시오
select last_name, job_id, department_id
from employees
where job_id like 'IT%';ex11) 커미션을 받는 사원들의 이름과 급여, 커미션을 출력하시오
( is null / is not null )
select last_name, salary, commission_pct
from employees
where commission_pct is not null;
-- commission_pct 컬럼이 NULL이 아니면 커미션을 받는다는 뜻이므로 출력시킨다.
-- 커미션을 받지 않는 사원들의 이름과 급여, 커미션 출력
select last_name, salary, commission_pct
from employees
where commission_pct is null;
ex12) 업무ID가 FI_MGR이거나 FI_ACCOUNT인 사원들의 사원번호, 이름, 직무를 출력하시오
( in연산자(or연산자의 다른표현) )
-- or 연산자 사용
select employee_id, last_name, job_id
from employees
where job_id='FI_MGR' or job_id='FI_ACCOUNT';
-- in 연산자 사용
select employee_id, last_name, job_id
from employees
where job_id in('FI_MGR', 'FI_ACCOUNT');
ex13) 급여가 10000이상 20000이하인 사원의 사원번호, 이름, 급여를 출력하시오
between연산자(and연산자의 다른 표현) : 초과, 미만에서는 사용할 수 없다
-- and 연산자
select employee_id, last_name, salary
from employees
where salary>=10000 and salary<=20000;
-- between ~ and 연산자
select employee_id, last_name, salary
from employees
where salary between 10000 and 20000;# 업무ID가 'SA_REP' 이거나 'AD_PRES' 이면서 급여가 10000를 초과하는 사원들의 이름, 업무ID, 급여를 출력하시오
# Employees테이블의 업무ID가 중복되지 않게 표시하는 질의를 작성하시오
#입사일이 2005년인 사원들의 사원번호, 이름, 입사일을 표시하시오
★ 2. 연산자
= : 같다
!=, ^=, <> : 같지 않다
>=, <=, >, < : 크거나 같다, 작거나 같다, 크다, 작다
and, or, between and, in, like, is null, is not null
#order by
order by : 정렬
asc - 오름차순(생략가능)
desc - 내림차순
컬럼명대신 컬럼번호로도 가능
- 오름차순일때, 출력되는 항목이 숫자일때는 123~ 정렬, 문자일때는 abc~ ㄱㄴㄷ~ 순으로 정렬된다.
ex1) 사원명, 부서ID, 입사일을 부서별로 내림차순 정렬하시오
select last_name, department_id, hire_date
from employees
order by 2 desc;
-- 2번 컬럼 기준으로 정렬
ex2) 사원명, 부서ID, 입사일을 부서별로 내림차순 정렬하시오
같은 부서가 있을때는 입사일순으로 정렬하시오
select last_name, department_id, hire_date
from employees
order by 2 desc, 3 asc;
-- 부서코드 내림차순으로 정렬 후,
-- 부서코드가 같은 항목들 끼리 입사일기준 오름차순으로 다시 정렬# 사원들의 연봉을 구한 후 연봉 순으로 내림차순 정렬하시오
[단일행 함수]
1. 숫자함수 : mod(나머지), round(반올림), trunc(내림), ceil(올림)
2. 문자함수 : lower, upper, length, substr, ltrim(왼쪽 공백 제거), rtrim(오른쪽 공백 제거), trim
3. 날짜함수 : sysdate(시스템 날짜), add_month(지금부터 몇 달 뒤), month_between(월과 월 사이에 흐른 시간)
[ 변환함수 ]
(1) 암시적(implict)변환 : 자동
VARCHAR2 또는 CHAR ------> NUMBER
VARCHAR2 또는 CHAR ------> DATE
NUMBER ------> VARCHAR2
DATE ------> VARCHAR2
(2) 명시적(explict)변환 : 강제
TO_NUMBER TO_DATE
<------ ------>
NUMBER CHARACTER DATE
------> <------
TO_CHAR TO_CHAR
[ 날짜형식 ]
YYYY : 네자리연도(숫자) (ex. 2005)
YEAR : 연도(문자)
MM : 두자리 값으로 나타낸 달 (ex. 01, 08, 12)
MONTH : 달 전체이름 (ex. January)
MON : 세자리 약어로 나타낸 달 (ex. Jan)
DY : 세자리 약어로 나타낸 요일 (ex. Mon)
DAY : 요일전체 (ex. Monday)
DD : 숫자로 나타낸 달의 일 (ex. 31, 01)
HH, HH24(24시간제)
MI
SS
[ 숫자형식 ]
9 : 숫자를 표시
0 : 0을 강제로 표시
$ : 부동$기호를 표시
L : 부동 지역통화기호 표시
. : 소수점출력
, : 천단위 구분자 출력
[ 그룹(집합)함수 ]
avg, sum, max, min, count
[ 기타함수 ]
nvl, dcode, case
ex1) 'Higgins'사원의 사원번호, 이름, 부서번호를 검색하시오
( 이름을 소문자로 바꾼후 검색 )
select employee_id, last_name, department_id
from employees
where lower(last_name)='higgins';
ex2) 10에서 3을 나눈 나머지 값 구하기
select mod(10,3) from dual;
-- dual은 따로 생성 할 필요 없이 한번쓰고 버려지는 일회용 가상 테이블
ex3) 35765.357을 반올림(round)
위치가 n일 때 n이 양수이면 (n+1)에서 반올림이 되고
n이 음수이면 n의 위치에서 반올림 된다
select round(35765.357, 2) from dual; --35765.36 (둘째 자리까지 표시)
select round(35765.357, 0) from dual; --35765
select round(35765.357, -3) from dual; --36000 (소수점 위로 3번째 자리에서 반올림 (7에서))
ex4) 35765.357을 내림(trunc)
위치가 n일 때 n이 양수이면 (n+1)에서 반올림이 되고
n이 음수이면 n의 위치에서 반올림 된다
select trunc(35765.357, 2) from dual; --35765.35
select trunc(35765.357, 0) from dual; --35765
select trunc(35765.357, -3) from dual; --35000
ex5) concat('문자열1','문자열2) : 문자열의 결합(문자열1+문자열2)
select concat('Hello', ' World') from dual;
ex6) length('문자열') : 문자열의 길이
lengthb('문자열') : 문자열의 바이트 수
char : 고정문자길이 ( 최대 2000바이트)
varchar2 : 가변문자길이 (최대 4000바이트)
-- 테이블 생성
create table text (
str1 char(20),
str2 varchar2(20));
-- 항목 입력
insert into text(str1,str2) values('angel','angel');
insert into text(str1,str2) values('사천사','사천사');
-- 커밋 (입력한 항목 저장)
commit;select lengthb(str1), lengthb(str2) from text;
[ 결과 ]
20 5 -- char는 문자길이가 고정이므로 항상 20바이트를 차지하고 있다.
20 9
select length(str1), length(str2) from text;[ 결과 ]
20 5
14 3 -- 'angel' 길이 : 5, '사천사' 길이 : 9 (한글 한 글자당 3)
ex7) 문자열 길이
select length('korea') from dual; -- 5
select length('코리아') from dual; -- 3
select lengthb('korea') from dual; -- 5
select lengthb('코리아') from dual; -- 9ex8) 지정한 문자열 찾기 : instr(표현식, 찾는문자, [위치]) 1:앞(생략가능), -1:뒤
( -1 : 뒤에서 첫번째 문자부터 역순으로 일치하는 문자를 찾아 뒤에서 부터 가장 가까운 문자를 찾아 인덱스 넘버 return)
# 문자열 찾기에선 대소문자를 가린다
select instr('HelloWorld', 'W') from dual; //6
select instr('HelloWorld', 'o', -5) from dual; //5
select instr('HelloWorld', 'o', -1) from dual; //7
select instr('HelloWorld', 'or', -1) from dual; //7
ex9) 지정한 길이의 문자열을 추출 : substr(표현식, 시작, [개수])
select substr('I am very happy', 6, 4) from dual; //very
select substr('I am very happy', 6) from dual; //very happy
# 사원의 레코드를 검색하시오(concat, length)
조건1) 이름과 성을 연결하시오(concat)
조건2) 구해진 이름의 길이를 구하시오(length)
조건3) 성이 n으로 끝나는 사원(substr)
ex10) 임의의 값이 지정된 범위 내에 어느 위치에 있는지를 찾는다
: width_bucket(표현식, 최소값, 최대값, 구간)
# 최소-최대값을 설정하고 10개의 구간을 설정 후 위치 찾기
0-100까지의 구간을 나눈 후 74가 포함되어 있는 구간을 표시하시오
select width_bucket(74, 0, 100, 10) from dual; //8
-- 0 부터 100까지 10개씩 끊어 74는 몇번째 구간에 들어가는지?
ex11) 공백제거 : ltrim(왼), rtrim(오른), trim(양쪽)
select rtrim('test ') || 'exam' from dual;
ex12) sysdate : 시스템에 설정된 시간표시
select sysdate from dual;
select to_char(sysdate, 'YYYY"년" MM"월" DD"일"') as 오늘날짜 from dual;
select to_char(sysdate, 'HH"시" MI"분" SS"초"') as 오늘날짜 from dual;
select to_char(sysdate, 'HH24"시" MI"분" SS"초"') as 오늘날짜 from dual;
ex13) add_months(date, 달수):날짜에 달수 더하기
select add_months(sysdate, 7) from dual;
--7개월 뒤
ex14) last_day(date) : 해당달의 마지막 날
select last_day(sysdate) from dual;
select last_day('2004-02-01') from dual;
select last_day('2005-02-01') from dual;
# 오늘부터 이번 달 말까지 총 남은 날수를 구하시오
ex15) months_between(date1,date2) : 두 날짜 사이의 달 수
select round(months_between('95-10-21', '94-10-20'), 0) from dual; -- 자동 형변환 date -> char
# 명시적인 변환(강제)
select last_name, to_char(salary, 'L99,999.00') -- L 화폐단위 표시
from employees
where last_name='King';
ex16) 년도 출력시 YY과 RR의 차이
-- 50 ~ 99년 사이 일 경우
select to_char(to_date('97/9/30', 'YY-MM-DD') , 'YYYY-MON-DD') from dual;← 2097
select to_char(to_date('97/9/30', 'RR-MM-DD') , 'RRRR-MON-DD') from dual;← 1997
-- 0 ~ 49년 사이 일 경우
select to_char(to_date('17/9/30', 'YY-MM-DD') , 'YYYY-MON-DD') from dual;← 2017
select to_char(to_date('17/9/30', 'RR-MM-DD') , 'RRRR-MON-DD') from dual;← 2017
# 2005년 이전에 고용된 사원을 찾으시오
ex17) fm형식:형식과 데이터가 반드시 일치해야함(fm - fm사이값만 일치)
fm를 표시하면 숫자앞의 0을 나타나지 않는다.
select last_name, hire_date from employees where hire_date='05/09/30';
select last_name, hire_date from employees where hire_date='05/9/30';
select to_char(sysdate, 'YYYY-MM-DD') from dual;
select to_char(sysdate, 'YYYY-fmMM-DD') from dual;
select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-MM-DD') from dual;← 2011-03-01
select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-fmMM-DD') from dual;← 2011-3-1
select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-fmMM-fmDD') from dual;← 2011-3-01
ex18) employees테이블에서 급여의 최대, 최소, 평균, 합을 구하시오
count(컬럼명), max(컬럼명), min(컬럼명), avg(컬럼명), sum(컬럼명) 함수
조건) 평균은 소수이하절삭, 합은 세자리마다 콤마찍고 ₩표시
select max(salary),
min(salary),
trunc(avg(salary),0), -- 소수 이하 절삭
to_char(sum(salary), 'L9,999,999') from employees;
# 커미션(commission_pct)을 받지 않은 사원의 인원수를 구하시오
ex19) employees테이블에서 없는 부서 포함해서 총 부서의 수를 구하시오
select department_id from employees; --← 107
select count(department_id) from employees; --← 106
select count(*) from employees;
select count(distinct department_id) from employees; --← 11
select count(distinct nvl(department_id, 0)) from employees; --← 12
select distinct nvl(department_id, 0) from employees; --← nvl명령어로 null값대신 0을 입력해준다.
# decode(표현식, 검색1,결과1, 검색2,결과2....[default])
표현식과 검색을 비교하여 결과 값을 반환 다르면 default
# case 구문
case value when 표현식 then 구문1
when 표현식 then 구문2
else 구문3
end case
# 업무 id가 'SA_MAN' 또는 ‘SA_REP'이면 'Sales Dept' 그 외 부서이면 'Another'로 표시
조건) 분류별로 오름차순 정렬
select job_id, decode(job_id,
'SA_MAN', 'Sales Dept',
'SA_REP', 'Sales Dept',
'Another') "분류"
from employees
order by 2;select job_id, case job_id
when 'SA_MAN' then 'Sales Dept'
when 'SA_REP' then 'Sales Dept'
else 'Another'
end "분류"
from employees
order by 2;select job_id, case
when job_id='SA_MAN' then 'Sales Dept'
when job_id='SA_REP' then 'Sales Dept'
else 'Another'
end "분류"
from employees
order by 2;# 급여가 10000미만이면 초급, 20000미만이면 중급 그 외면 고급을 출력하시오
(case 사용)
조건1) 제목은 사원번호, 사원명, 구분으로 표시하시오
조건2) 구분(오름차순)으로 정렬하고, 같으면 사원명(오름차순)으로 정렬하시오
select employee_id as 사원번호,
last_name as 사원명,
salary as 월급,
case
when salary < 10000 then '초급'
when salary < 20000 then '중급'
else '고급'
end "구분"
from employees
order by 4 desc, 3 asc, 2; -- 3열 오름차순, 그다음에 2열 알파벳 오름차순
-- ascending 오름차순 descending 내림차순ex21) rank함수 : 전체값을 대상으로 순위를 구함
rank(표현식) within group(order by 표현식)
rank() over(쿼리파티션) → 전체순위를 표시
급여가 3000인 사람의 상위 급여순위를 구하시오
select rank(3000) within group(order by salary desc) "rank" from employees;
select rank(3000) within group(order by salary desc) "rank" from employees;
전체사원의 급여순위를 구하시오
select employee_id, salary, rank() over(order by salary desc)"rank" from employees;
select employee_id, salary, rank() over(order by salary desc)"rank" from employees;
ex22) first_value함수 : 정렬된 값중에서 첫번째값 반환
first_value(표현식) over(쿼리파티션)
전체사원의 급여와 함께 각부서의 최고급여를 나타내고 비교하시오
select employee_id,
salary,
department_id,
first_value(salary) over(partition by department_id order by salary desc) "highsal_deptID"
from employees;
# PARTITION BY 절은 GROUP BY 절과 동일한 역할을 진행 한다.
단, GROUP BY 절을 사용하지 않고 필요한 집합으로 행들을 그룹화 시킴
Partition by 절을 사용 함으로 GROUP BY 절 없이 다양한 GROUPING 집합의 집계 결과들을 함께 출력 할 수 있다.
ORDER BY 절은 Partition by 로 정의된 WINDOW 내에서의 행들의 정렬 순서를 정의 한다.
select employee_id,
last_name,
salary,
department_id,
row_number( ) over ( PARTITION BY department_id ORDER BY salary DESC ) rnum
from employees ;
--부서 번호가 바뀔 때 Row Number 는 새로 시작 된다.
--NULL 값은 정렬 시 가장 큰 값으로 인식 (기본설정)
# 사원테이블에서 사원번호, 이름, 급여, 커미션, 연봉을 출력하시오
조건1) 연봉은 $ 표시와 세자리마다 콤마를 사용하시오
조건2) 연봉 = 급여 * 12 + (급여 * 12 * 커미션)
조건3) 커미션을 받지 않는 사원도 포함해서 출력하시오
select employee_id as 사원번호,
last_name as 이름,
salary as 급여,
nvl(commission_pct,0) as 커미션,
to_char( salary * 12 + (salary * 12 * nvl(commission_pct,0)), '$00,0000') as 연봉
from employees;
-- nvl 값이 null이면 대신 콤마 뒤의 값을 입력 nvl( ,0)
# 매니저가 없는 사원의 MANAGER_ID를 1000번으로 표시
조건1) 제목은 사원번호, 이름, 매니저ID
조건2) 모든 사원을 표시하시오
select employee_id as 사원번호,
last_name as 여름,
nvl(manager_id, 1000) as 매니저ID
from employees;
--3
★ 3. 그룹함수
# 기본 구조
select [distinct] [컬럼1, 컬럼2,.....][as 별명][ || 연산자][*] --- 6
from 테이블명 --- 1
[where 조건절] --- 2
[group by 컬럼명] --- 3
[having 조건절] --- 4
[order by 컬럼명 asc | desc ] --- 5
- COUNT( Column ) : 행의 수 반환
- AVG( Column ) : 행의 평균
- SUM( Column ) : 총 합계
- MAX( Column ) : 최대값 반환
- MIN( Column ) : 최소값 반환
- VARIANCE( Column ) : 분산 계산
- STDDEV( Column ) : 표준 편차 계산
- group by ( Column ) : 그룹함수 (max,min,sum,avg,count...) 와 같이 사용
- having ( Column ) : 묶어놓은 그룹의 조건절
# 사원테이블에서 급여의 평균을 구하시오
조건) 소수 이하는 절삭, 세자리 마다 콤마(,) 표시
더보기# 예제
select to_char(trunc(avg(salary),0), '99,999') as 사원급여평균 from employees;# trunc( ~ , 0) 0자리 이하에서 반올림 ( -1 : 10, -2 : 100, 1: 0.1, 2 : 0.01 )
# to_char( ~ , '999,999) 해당 형식으로 출력
( 000 이면 값의 자리수가 적을시 앞에 0을 출력 # 001,234 )
( L999,999 : L은 화폐 기호 표시)
# as "~" : 해당 행의 이름대신 "" 안의 문자열로 명시
# 부서별 급여평균을 구하시오
조건1) 소수 이하는 반올림
조건2) 세자리 마다 콤마, 화폐 단위(₩)로 표시
조건3) 부서별로 오름차순 정렬하시오
조건4) 평균급여가 5000이상인 부서만 표시하시오
더보기# 예제
select department_id as 부서코드, to_char(trunc(avg(salary),0),'L999,999') as 평균급여 -- 소수 이하 반올림, 세자리마다 콤마 FROM employees group by department_id having avg(salary) >= 5000 --평균 급여 5000이상만 표시 order by 부서코드 asc; -- 부서코드 오름차순# asc : 오름차순 정렬( ascending ) 123~ abc ~ ㄱㄴㄷ~
# desc : 내림차순 정렬 ( descending )
# job_id별 급여의 합계를 구해서 job_id, 급여합계를 출력하시오
더보기# 예제
select job_id, sum(salary) as 급여합계, avg(salary) as 급여평균 from employees group by job_id -- having job_id in('AD_VP', 'FI_ACCOUNT'); --> job_id컬럼이 'AD_VP', 'FI_ACCOUNT' 인 열(row)만 출력
# 10과 20 부서에서 최대급여를 받는 사람의 최대급여를 구하여 정렬하시오
department_id max_salary
------------------------------------
10 4400
20 13000
더보기# 예제
-- 방법 1 select department_id, max(salary) from employees group by department_id having department_id in(10, 20) --having department_id = 10 or department_id = 20 --위 코드와 같음 order by 1; -- 방법 2 select department_id, max(salary) as max_salary from employees where department_id in(10,20) group by department_id order by department_id;# order by 1 : 1행 기준으로 정렬
# in(10, 20) : department_id가 10 또는 20인 행 출력. or연산자와 역할이 같다.
# having, where : 출력 할 행 조건 명시, (having은 그룹함수에서만 쓴다.)
# self JOIN
#자기자신의 테이블과 조인하는 경우 사원과 관리자를 연결하시오
조건) employee_id = manager_id사원번호 사원이름 관리자
----------------------------------
101 Kochhar King
-------------------------------------------------------------------
employee_id, last_name(사원이름) last_name(관리자)
더보기# 예제
-- 방법 1 select e.employee_id, e.last_name as 직원, e.manager_id as 매니저코드, m.last_name as 담당매니저 from employees e join employees m on(m.employee_id = e.manager_id) order by 3, 1; -- 컬럼 3을 1순위로 오름차순 정렬 후, 컬럼 1 오름차순 정렬 -- 방법 2 select e.employee_id as 사원번호, e.last_name as "담당 매니저", m.manager_id as 매니저코드, m.last_name as "사원이름" from employees e, employees m where e.employee_id = m.manager_id order by e.employee_id, m.manager_id; -- e.employee_id 정렬 후, m.manager_id 정렬as " ~ " : 띄어쓰기 없이는 따옴표 생략 가능
# CROSS JOIN
#cross join : 모든 행에 대해 가능한 모든 조합을 생성하는 조인
더보기# 예제
-- 방법 1 select * from countries, locations; -- 방법 2 select * from countries cross join locations;
# Non Equijoin
# 컬럼값이 같은 경우가 아닌 범위에 속하는지 여부를 확인 할 때
on ( 컬럼명 between 컬럼명1 and 컬럼명2)
더보기# 예제
create table salgrade( salvel varchar2(2), lowst number, highst number); insert into salgrade values('A', 20000, 29999); insert into salgrade values('B', 10000, 19999); insert into salgrade values('C', 0, 9999); commit; select * from salgrade; select last_name, salary, salvel from employees join salgrade on(salary between lowst and highst) order by salary desc;
# n(여러)개의 테이블을 JOIN
업무ID 같은 사원들의 사원이름, 업무내용, 부서이름을 출력하시오
(EMPLOYEES, JOBS, DEPARTMENTS 테이블을 조인)
EMPLOYEES JOBS DEPARTMENTS
------------------------------------------------------------
department_id job_id department_id
job_id
더보기# 예제
select last_name, job_title, department_name from employees join departments using(department_id) join jobs using(job_id);
# [문제3] 위치ID, 부서ID을 연결해서 사원이름, 도시, 부서이름을 출력하시오
(관련 테이블 : EMPLOYEES, LOCATIONS2, DEPARTMENTS)
조건1 : 사원이름, 도시, 부서이름으로 제목을 표시하시오
조건2 : Seattle 또는 Oxford 에서 근무하는 사원
조건3 : 도시 순으로 오름차순 정렬하시오더보기# 예제
select last_name as 사원이름, city as 도시, department_name as 부서이름 from employees join departments d using(department_id) join locations2 l on(d.location_id = l.loc_id) where city in ('Seattle', 'Oxford') --where city = 'Seattle' or city = 'Oxford' 같음 order by city asc , 1; -- 도시이름 정렬 후, 이름 정렬
# [문제4] 부서ID, 위치ID, 국가ID를 연결해서 다음과 같이 완성하시오
(관련 테이블 : EMPLOYEES, LOCATIONS2, DEPARTMENTS, COUNTRIES)
조건1 : 사원번호, 사원이름, 부서이름, 도시, 도시주소, 나라이름으로 제목을 표시하시오
조건2 : 도시주소에 Ch 또는 Sh 또는 Rd가 포함되어 있는 데이터만 표시하시오
조건3 : 나라이름, 도시별로 오름차순 정렬하시오
조건4 : 모든 사원을 포함한다더보기# 예제
select e.employee_id as 사원번호, e.last_name as 이름, d.department_name as 부서이름, l.city as 도시, l.STREET_ADDRESS as 주소, c.COUNTRY_NAME as 국가 from employees e left join DEPARTMENTS d using(department_id) join LOCATIONS2 l on(location_id = l.loc_id) -- location_id는 다른 테이블과 공유하므로 d. 명시 생략 가능 join COUNTRIES c on(l.COUNTRY_ID = c.COUNTRY_ID) -- = using(COUNTRY_ID) where STREET_ADDRESS like '%Ch%' or STREET_ADDRESS like '%Sh%' or '주소' like '%Rd%' -- in은 사용 불가(in 안에 like를 쓸 수 없다. 등호식을 써야 가능) order by 6, 4; -- = order by '국가', '도시';
★ 4. 집합연산자
두개 이상의 쿼리결과를 하나로 결합시키는 연산자
1. UNION : 양쪽쿼리를 모두 포함(중복 결과는 1번만 포함) → 합집합 (자동 sort)
2. UNION ALL : 양쪽쿼리를 모두 포함(중복 결과도 모두 포함) (sort 시키지 않음)
3. INTERSECT : 양쪽쿼리 결과에 모두 포함되는 행만 표현 → 교집합
4. MINUS : 쿼리1결과에 포함되고 쿼리2결과에는 포함되지 않는 행만 표현
→ 차집합오라클의 집합연산자(SET operator) UNION, INTERSECT, MINUS 는 order by 한다
→ 컬럼이 많으면 order by 하므로 느려진다.
수가 작은 튜플로 가공 후 사용 하는게 좋다
→ UNION ALL은 order by 하지 않고 무조건 합해준다
Order by를 하려면 두번째 쿼리에 작성해야 한다
-- 테이블 구조만 복사 내용물은 복사되지 않음.
create table employees_role as select * from employees where 1=0;
-- 테이블 전체를 그대로 복사
create table locations2 as select * from locations;
-- 출력
select * from employees_role;# 항목 추가
insert into employees_role values(101, 'Neena', 'Kochhar', 'NKOCHHAR', '515.123.4568', '1989-09-21', 'AD_VP', 17000.00, NULL, 100, 90);
insert into employees_role values(101, 'Neena', 'Kochhar', 'NKOCHHAR', '515.123.4568', '1989-09-21', 'AD_VP', 17000.00, NULL, 100, 90);
insert into employees_role values(101, 'Nee', 'Ko', 'NKOCHHAR', '515.123.4568', '1989-09-21', 'AD_VP', 17000.00, NULL, 100, 90);
insert into employees_role values(200, 'Neena', 'Kochhar', 'NKOCHHAR', '515.123.4568', '1989-09-21', 'AD_VP', 17000.00, NULL, 100, 90);
insert into employees_role values(200, 'Nee', 'Kochhar', 'NKOCHHAR', '515.123.4568', '1989-09-21', 'AD_VP', 17000.00, NULL, 100, 90);
insert into employees_role values(300, 'GilDong', 'Conan', 'CONAN', '010-123-4567', '2009-03-01', 'IT_PROG', 23000.00, NULL, 100, 90);ex1) union
employee_id, last_name이 같을 경우 중복제거 하시오 → 110 레코드
employee_id, last_name이 같을 경우 중복제거 하시오 → 110 레코드
select employee_id, last_name from employees
union
select employee_id, last_name from employees_role;
ex2) union all
employee_id, last_name이 같을경우 중복을 허용 하시오 → 113 레코드
select employee_id, last_name from employees
union all
select employee_id, last_name from employees_role;
--
select salary from employees where department_id=10
union all
select salary from employees where department_id=30 order by 1;ex3) minus
employees_role과 중복되는 레코드는 제거하고 employees에만 있는 사원명단을 구하시오 (단, employee_id, last_name만 표시) → 106 레코드
select employee_id, last_name from employees
minus
select employee_id, last_name from employees_role;ex4) intersect
employees와 employees_role에서 중복되는 레코드의 사원명단을 구하시오
(단, employee_id, last_name만 표시) → 1 레코드
select employee_id, last_name from employees
intersect
select employee_id, last_name from employees_role;# employees와 employees_role에서 레코드의 사원명단을 구하시오
조건1) 사원이름, 업무ID, 부서ID을 표시하시오
조건2) employees 에서는 부서ID가 10인사원만
employees_role에서는 업무ID가 IT_PROG만 검색
조건3) 중복되는 레코드는 제거
select last_name, job_id, department_id
from employees
where department_id = 10
union
select last_name, job_id, department_id
from employees_role
where job_id = 'IT_PROG';
ex5) SET operator과 IN operator관계
job_title이 'Stock Manager' 또는 'Programmer'인 사원들의 사원명과 job_title을 표시하시오
--방법1 (join, in연산자 이용)
select last_name, job_title
from employees
join jobs using(job_id)
where job_title in('Stock Manager','Programmer');
--방법2 (join, union 이용)
select last_name, job_title
from employees
join jobs using(job_id)
where job_title='Stock Manager'
union
select last_name, job_title
from employees
join jobs using(job_id)
where job_title='Programmer'
order by 2;
ex9) 컬럼명이 다른경우의 SET operator
쿼리1과 쿼리2의 select 목록은 반드시동일(컬럼개수, 데이터타입)해야 하므로 이를 위해 Dummy Column을 사용할수 있다
select last_name, employee_id, hire_date
from employees
where department_id=20
union
select department_name, department_id, NULL -- NULL은 hire_date를 대체하는 더미
from departments
where department_id=20;employees 의 last_name과 departments 의 department_name은 둘다 같은 varchar 형식이므로
같은 컬럼에서 출력시킬 수 있다.
★하위질의 (SubQuery)
하나의 쿼리에 다른 쿼리가 포함되는 구조, ()로처리
1) 단일행 서브쿼리(단일행반환) : > , < , >=, <= , <>
Main Query
Sub Query -----> 1개결과
2) 다중행 서브쿼리(여러행반환) : in, any, all
Main Query
Sub Query -----> 여러개의 결과
< any : 비교대상중 최대값보다 작음
> any : 비교대상중 최소값보다 큼
(ex. 과장직급의 급여를 받는 사원조회)
= any : in연산자와 동일
< all : 비교대상중 최소값보다 작음
> all : 비교대상중 최대값보다 큼
(ex. 모든과장들의 직급보다 급여가 많은 사원조회)
3) 상관쿼리(correlated subquery) boolean만 리턴 컬럼명이 필요 x
: EXIST 연산자는 하위 쿼리에 레코드가 있는지 테스트하는 사용된다
: EXIST 연산자는 하위 쿼리가 하나 이상의 레코드를 반환하면 true를 반환
: EXIST 연산자는 일반적으로 상관 관계가 있는 하위 쿼리와 함께 사용
: EXIST 연산자는 거의 * 로 구성된다
하위쿼리에 지정된 조건을 충족시키는 행이 있는지 없는지를 테스트하기 때문에 열이름을 나열 할 의미가 없다
ex1) Neena사원의 부서명을 알아내시오
select department_id from employees where first_name='Neena';
select department_name from departments where department_id=90;
select department_name from departments
where department_id = (select department_id // Neena 사원의 부서코드만 선택
from employees
where first_name='Neena');
--단일행 subQuery 결과가 한줄나온다.ex2) Neena사원의 부서에서 Neena사원보다 급여를 많이 받는 사원들의 last_name, department_id, salary 구하시오 (90, 17000)
select last_name, department_id, salary
from employees
where department_id = (select department_id from employees
where first_name='Neena')
and salary > (select salary from employees where first_name='Neena');# 최저급여를 받는 사원들의 이름과 급여를 구하시오
-- salary를 오름차순 정렬 해, 맨 첫 항목만 출력하기. (최저급여가 여럿일경우 x)
select last_name, salary
from (select * from employees order by salary)
where rowNum = 1;
-- 서브쿼리 이용
select last_name, salary from employees where salary = (select min(salary) from employees);
# 부서별 급여 합계 중 최대급여를 받는 부서의 부서명과 급여합계를 구하시오 (group by)
select department_name, sum(salary)
from employees
join departments using(department_id)
group by department_name
having sum(salary) = (select max(sum(salary)) from employees
group by department_id); -- // 조건식에 넣은 코드가 리턴하는 값은 하나이어야하 한다. (단행쿼리이어야 한다.)
-- group 함수에는 where 사용 불가
ex3) Austin과 같은 부서이면서 같은 급여를 받는 사원들의
이름, 부서명, 급여를 구하시오 (60부서, 4800달러)
select last_name, department_name, salary
from employees
join departments using(department_id) -- join 을 left join으로 해도 결과가 같다.
where department_id = (select department_id
from employees
where last_name='Austin')
and
salary = (select salary from employees where last_name='Austin');ex4) 'ST_MAN' 직급보다 급여가 많은 'IT_PROG' 직급의 last_name, job_id, salary 직원들을 조회하시오
select last_name, job_id, salary
from employees
where job_id = 'IT_PROG' and
salary >any(select salary from employees where job_id='ST_MAN');# 'IT_PROG' 직급 중 가장 많이 받는 사원의 급여보다 더 많은 급여를 받는 'FI_ACCOUNT' 또는 'SA_REP' 직급 직원들을 조회하시오
조건1) 급여 순으로 내림차순 정렬하시오
조건2) 급여는 세자리 마다 콤마(,) 찍고 화폐단위 '원’을 붙이시오
조건3) 타이틀은 사원명, 업무ID, 급여로 표시하시오
select last_name as 사원명, job_id as 업무ID, to_char(salary*1107, '999,999,999')||'원' as 급여
from employees
where (job_id = 'FI_ACCOUNT' or job_id = 'SA_REP') and
salary > all (select salary from employees where job_id = 'IT_PROG')
order by salary desc;ex5) 'IT_PROG'와 같은 급여를 받는 사원들의 이름, 업무ID, 급여를 전부 구하시오
select last_name, job_id, salary
from employees
where salary in(select salary from employees where job_id='IT_PROG');
ex6) 전체직원에 대한 관리자와 직원을 구분하는 표시를 하시오
--방법1 (in 연산자)
select employee_id as 사원번호, last_name as 이름,
case
when employee_id in(select manager_id from employees)
then '관리자'
else '직원'
end as 구분
from employees
order by 3,1;
--방법2 (union, in, not in 연산자)
select employee_id as 사원번호, last_name as 이름, '관리자' as 구분
from employees
where employee_id in(select manager_id from employees)
union
select employee_id as 사원번호, last_name as 이름, '직원' as 구분
from employees
where employee_id not in(select manager_id from employees where manager_id is not null)
order by 3,1;
-- 방법3 (상관쿼리이용)
-- 메인쿼리 한행을 읽고 해당값을 서브쿼리에서 참조하여 서브쿼리 결과에 존재하면 true를 반환
select employee_id as 사원번호, last_name as 이름, '관리자' as 구분
from employees e
where exists(select null from employees where e.employee_id=manager_id)
union
select employee_id as 사원번호, last_name as 이름, '직원' as 구분
from employees e
where not exists(select null from employees where e.employee_id=manager_id)
order by 3,1;
[문제4] 자기 업무id(job_id)의 평균급여를 받는 직원들을 조회하시오
조건1) 평균급여c는 100단위 이하 절삭하고 급여는 세자리마다 콤마, $표시
조건2) 사원이름(last_name), 업무id(job_id), 직무(job_title), 급여(salary) 로 표시하시오
조건3) 급여순으로 오름차순 정렬하시오
select last_name as 사원명, job_id as 업무ID, job_title, to_char(salary, '$999,999') as 급여
from employees
join jobs using(job_id)
where (job_id, salary) in (select job_id, trunc(avg(salary), -3) from employees group by job_id)
order by 4;
ex7) group by rollup : a,b별 집계(Subtotal 구하기)
부서별, 직무ID별 급여평균구하기(동일부서에 대한 직무별 평균급여)
조건1) 반올림해서 소수 2째자리까지 구하시오
조건2) 제목은 Job_title, Department_name, Avg_sal로 표시하시오
select department_name, job_title, round(avg(salary), 2) as "Avg_sal"
from employees
join departments using(department_id)
join jobs using(job_id)
group by rollup(department_name, job_title);
ex8) group by cube : a별 집계 또는 b별 집계
부서별, 직무ID별 급여평균구하기(부서를 기준으로 나타내는 평균급여)
select department_name, job_title, round(avg(salary), 2) as "Avg_sal"
from employees
join departments using(department_id)
join jobs using(job_id)
group by cube(department_name, job_title);
ex9) group by grouping sets
직무별 평균급여와 전체사원의 평균급여를 함께 구하시오
select job_title, round(avg(salary), 2) as "Avg_sal"
from employees
join departments using(department_id)
join jobs using(job_id)
group by grouping sets((job_title),()); ← () All Rows의 역활
★ 6. 테이블 생성
create table 테이블명(컬럼명1 컬럼타입 [제약조건],
컬럼명2 컬럼타입 [제약조건],.....);
# 테이블명
- 문자로 시작(30자이내) : 영문 대소문자, 숫자, 특수문자( _ , $ , # ), 한글
- 중복되는 이름은 사용 안됨
- 예약어(create, table, column등)은 사용할 수 없다
- 자료형
number : number(전체자리, 소수이하), number → 숫자형(가변형)
int : 정수형 숫자(고정형)
varchar/varchar2 : 문자, 문자열(가변형) → 최대 4000byte
char : 문자, 문자열(고정형) → 2000byte
date : 날짜형
clob : 문자열 → 최대4GB
blob : 바이너리형(그림, 음악, 동영상..) → 최대4GB (db에는 동영상, 사진은 넣지 않으므로 blob은 쓰이지 않는다.)
(웹하드에 업로드 후 그 주소를 db에 저장)
- 제약조건
not null : 해당 컬럼에 NULL을 포함되지 않도록 함 (컬럼)
unique : 해당 컬럼 또는 컬럼 조합 값이 유일하도록 함 (컬럼, 테이블)
primary key : 각 행을 유일하게 식별할 수 있도록 함 (컬럼, 테이블) - 같은 열에서 유일한 값이 되도록 한다.
references table(column) :
해당 컬럼이 참조하고 있는 (부모)테이블의 특정 (컬럼, 테이블) 컬럼 값들과
일치하거나 또는 NULL이 되도록 보장함
check : 해당 컬럼에 특정 조건을 항상 만족시키도록 함 (컬럼, 테이블)
[참고] primary key = unique + not null
ex) 제약조건 설정 예시
idx 일련번호 primary key
id 아이디 unique
name 이름 not null
phone 전화번호
address 주소
score 점수 check
subject_code 과목코드
hire_date 입학일 기본값(오늘날짜)
marriage 결혼 check
- 제약조건 확인
constraint_name:이름
constraint_type:유형
p : primary key
u : unique
r : reference
c : check, not null
search_condition : check조건 내용
r_constraint_name : 참조테이블의 primary key 이름
delete_rule : 참조테이블의 primary key 컬럼이 삭제될 때 적용되는 규칙
(no action, set null, cascade등)
- 삭제 RULE
on delete cascade
: 대상 데이터를 삭제하고, 해당 데이터를 참조하는 데이터도 삭제
on delete set null
: 대상 데이터를 삭제하고, 해당 데이터를 참조하는 데이터는 NULL로 바꿈
on delete restricted
: 삭제대상 데이터를 참조하는 데이터가 존재하면 삭제할 수 없음(기본값)
- 수정 RULE
on update cascade
: 대상 데이터를 수정하면, 해당 데이터를 참조하는 데이터도 수정
[테이블수정]
-구문-
alter table 테이블명
add 컬럼명 데이터타입 [제약조건]
add constraint 제약조건명 제약조건타입(컬럼명)
modify 컬럼명 데이터타입
drop column 컬럼명 [cascade constraints]
drop primary key [cascade] | union (컬럼명,.....) [cascade] .... | constraint 제약조건명 [cascade]
-이름변경-
alter table 기존테이블명 rename to 새테이블명
rename 기존테이블명 to 새테이블명
alter table 테이블명 rename column 기존컬럼명 to 새컬럼명
alter table 테이블명 rename constraint 기존제약조건명 to 새제약조건명
[테이블복사]
- 서브쿼리를 이용한 테이블 생성및 행(레코드) 복사
- 서브쿼리를 이용해서 복사한경우 not null을 제외한 제약조건은 복사 안됨
(not null제약조건도 sys_*****로 복사됨)
- 구문 -
create table 테이블명([컬럼명1,컬럼명2.....]) as 서브쿼리
- 구조만 복사 -
create table 테이블명1 as select * from 테이블명2 where 1=0
[시퀀스]
순차적으로 정수값을 자동으로 생성하는 객체
create sequence 시퀀스명
[increment by 증가값] [start with 시작값]
[maxvalue 최대값 | minvalue 최소값]
[cycle | nocycle]
[cache | nocache]
- increment by 증가값 : 증가/감소 간격(기본값 : 1)
- start with : 시작번호(기본값 : 1)
- maxvalue / minvalue : 시퀀스의 최대/최소값지정
- cycle/nocycle : 최대/최소값에 도달 시 반복여부결정
- cache / nocache : 지정한 수량만큼 메모리 생성여부결정 (최소값:2, 기본값:20)
[ insert ]
: 테이블에 데이터(새로운행)추가
insert into 테이블명 [ (column1, column2, .....)] values (value1,value2,.....)
- column과 values의 순서일치
- column과 values의 개수 일치
[ update ]
: 테이블에 포함된 기존 데이터수정
전체 데이터 건수(행수)는 달라지지 않음
조건에 맞는 행(또는 열)의 컬럼값을 갱신할 수 있다
update 테이블명 set 컬럼명1=value1, 컬럼명2=value2 ..... [where 조건절]
- where 이 생략이 되면 전체행이 갱신
- set절은 서브쿼리 사용가능, default옵션 사용가능
[ delete ]
: 테이블에 포함된 기존데이터를 삭제
행 단위로 삭제되므로 전체행수가 달라짐
delete [from] 테이블명 [where 조건절];
- where을 생략하면 전체행이 삭제됨
- 데이터는 삭제되고 테이블 구조는 유지됨
[ truncate ]
: 테이블의 데이터를 전부 삭제하고 사용하고 있던 공간을 반납
해당 테이블의 데이터가 모두 삭제되지만 테이블 자체가 지워지는 것은 아님
해당 테이블에 생성되어 있던 인덱스도 함께 truncate 됨

DELETE 후에는 데이터만 지워지고 쓰고 있던 디스크 상의 공간은 그대로 가지고 있다.
TRUNCATE 작업은 최초 테이블이 만들어졌던 상태, 즉 데이터가 1건도 없는 상태로 모든 데이터 삭제, 칼럼 값만 남아 있다.
그리고 용량도 줄고 인덱스 등도 모두 삭제된다.
→ DELETE보다 TRUNCATE가 더 좋아 보이나 DELETE는 where를 이용하여 원하는 데이터만 골라서 삭제가 가능하나 TRUNCATE는 조건을 사용할 수 없다. 또 DDL이기 때문에 사용권한 문제도 있다.
DROP 명령어는 데이터와 테이블 전체를 삭제하게 되고
사용하고 있던 공간도 모두 반납하고 인덱스나 제약조건 등 오브젝트로 삭제 된다
[ transaction처리 ]
commit 하기 이전까지 입력한 명령어들
: 일의 시작과 끝이 완벽하게 마무리(commit)
처리도중 인터럽트(interrupt:장애)가 발생하면 되돌아옴(rollback)
ex1) 테이블 : test
create table test(
id number(5),
name char(10),
address varchar2(50));ex2) 테이블 : user1
create table user1(
idx number primary key,
id varchar2(10) unique,
name varchar2(10) not null,
phone varchar2(15),
address varchar2(50),
score number(6,2) check(score >=0 and score <= 100),
subject_code number(5),
hire_date date default sysdate,
marriage char(1) default 'N' check(marriage in('Y','N'))
);ex3) 제약조건 확인
select constraint_name, constraint_type -- name과 type 만 출력
from user_constraints
where table_name='USER1';
----------------------------------------------
select * -- constraint 항목 모두 출력
from user_constraints
where table_name='USER1';ex4) 테이블
create table user2(
idx number constraint PKIDX primary key, -- constraint_name 을 지정
id varchar2(10) constraint UNID unique,
name varchar2(10) constraint NOTNAME not null,
phone varchar2(15),
address varchar2(50),
score number(6,2) constraint CKSCORE check(score >=0 and score <= 100),
subject_code number(5),
hire_date date default sysdate,
marriage char(1) default 'N' constraint CKMARR check(marriage in('Y','N'))
);ex5) 제약조건 확인
select constraint_name, constraint_type
from user_constraints
where table_name='USER2';
select *
from user_constraints
where table_name='USER2';ex6) 추가
insert into user1(idx,id,name,phone,address,score,subject_code,hire_date,marriage)
values(1,'aaa','kim','010-000-0000','서울',75,100,'2010-08-01','Y');
insert into user1(idx,id,name,phone,address,score,subject_code,hire_date,marriage)
values(1,'aaa','kim','010-000-0000','서울',75,100,'2010-08-01','Y');
→ 무결성제약조건에 위배(이유: idx 1 중복)
insert into user1(idx,id,name,phone,address,score,subject_code,hire_date,marriage)
values(2,'aaa','kim','010-000-0000','서울',75,100,'2010-08-01','Y');
→ 무결성제약조건에 위배(이유: id aaa 중복)
insert into user1(idx,id,name,phone,address,score,subject_code,hire_date,marriage)
values(2,'bbb','','010-000-0000','서울',75,100,'2010-08-01','Y');
→ NULL을 ("HR"."USER1"."NAME") 안에 삽입할 수 없습니다
insert into user1(idx,id,name,phone,address,score,subject_code,hire_date,marriage)
values(2,'bbb','lee','010-000-0000','서울',120,100,'2010-08-01','Y');
→ 체크제약조건에 위배되었습니다(이유: score가 0~100사이의 수 이어야함)
insert into user1(idx,id,name,phone,address,score,subject_code,hire_date,marriage)
values(2,'bbb','lee','010-000-0000','서울',75,100,'2010-08-01','K');
→ 체크제약조건에 위배되었습니다(이유:marriage가 Y 또는 N이어야함)
insert into user1(idx,id,name,phone,address,score,subject_code,hire_date,marriage)
values(2,'bbb','lee','010-000-0000','서울',75,100,'2010-08-01','N');ex7) 테이블 목록 확인
select * from tab;
ex8) 테이블의 내용확인
select * from user1;
select * from user2;ex9) 테이블의 구조 확인
desc user1;
describe user1;ex10) 시퀀스 목록 확인
select * from user_sequences;
ex11) 테이블명 변경 : test → user3
alter table test rename to user3;
ex12) 컬럼추가 : user3 → phone varchar2(15)
alter table user3 add phone varchar2(15);
desc user3;
ex13) 제약조건 추가 : user3 → id에 unique, 제약조건명 UID2
alter table user3 add constraint UID2 unique(id);
select constraint_name, constraint_type
from user_constraints
where table_name='USER3';
ex14) 제약조건 삭제 - alter table 테이블명 drop constraint 제약조건명;
alter table user3 drop constraint UID2;
alter table user3 DROP constraint SYS_C007693;
select *
from user_constraints
where table_name='USER3';
ex15) 컬럼 추가 : user3 → no number (PK 설정)
alter table user3 add no number primary key;
desc user3
ex16) 구조 변경 : user3 → name char(10) 를 varchar2(10)로 바꿈
alter table user3 modify name varchar2(10);
desc user3
ex17) 컬럼 삭제 : user3 → address
alter table user3 drop column address;
desc user3
ex18) 테이블삭제 / 휴지통비우기: user3
drop table user3;
purge recyclebin; → 휴지통 비우기
drop table user3 purge; → 휴지통에 넣지 않고 바로 삭제
show recyclebin;
flashback table user3 to before drop; → 휴지통에서 되살리기
flashback table "BIN$cEf2dC1fRhilpiULWNRf3A==$0" to before drop;
select * from recyclebin; → 휴지통에 테이블 정보 검색
ex19) 시퀀스 생성 / 삭제
create sequence idx_sql increment by 2 start with 1 maxvalue 9 cycle nocache;
-- 1부터 9까지 2씩 증가 (1, 3, 5, 7, 9, 1, 3, ....)
select idx_sql.nextval from dual; → 다음 시퀀스값 표시(nextval)
select idx_sql.currval from dual; → 현재 시퀀스값 표시(currtval)
select * from user_sequences;
drop sequence idx_sql;
ex20) 테이블생성과 시퀀스 적용
create table book(
no number primary key,
subject varchar2(50),
price number,
year date);
create sequence no_seq increment by 1 start with 1 nocycle nocache;
insert into book(no,subject,price,year)
values(no_seq.nextval,'오라클 무작정 따라하기',10000,sysdate);
insert into book(no,subject,price,year)
values(no_seq.nextval, '자바 3일 완성',15000,'2007-03-01');
insert into book values(no_seq.nextval, 'JSP 달인 되기',18000,'2010-01-01');
select * from book;ex21) 테이블 구조만 복사
create table user3 as select * from user2 where 1=0;
desc user3;
select constraint_name, constraint_type, search_condition
from user_constraints
where table_name='USER3';
--← not null을 제외하고는 제약조건이 복사 안됨
--← not null 제약조건도 sys_*****로 복사됨
ex22) 테이블(idx → bunho, name → irum, address → juso) 을 복사하고 id가 bbb인 레코드를 복사하시오
원본테이블 : user1 / 사본테이블 : user4
create table user4(bunho, irum, juso)
as select idx, name, address from user1 where id='bbb';
select * from user4;
ex23) 테이블 생성 후 행 추가
테이블명 : dept
deptno number → 기본키, 제약조건명(DNO)
dname varcahr2(30) → 널 허용안됨, 제약조건명(DNAME)
테이블명 : emp
empno number → 기본키,제약조건명(ENO)
ename varchar2(30) → 널허용안됨, 제약조건명(ENAME)
deptno number → 외래키, 제약조건명(FKNO),
대상데이터를 삭제하고 참조하는 데이터는 NULL로 바꿈
create table dept(
deptno number constraint DNO primary key,
dname varchar2(30) constraint DNAME not null);
create table emp(
empno number constraint ENO primary key,
ename varchar2(30) constraint ENAME not null,
deptno number,
constraint FKNO foreign key(deptno) references dept on delete set null);
# foreign key(deptno) references dept - 참조 키 ( references 하는 테이블의 같은 항목 값을 참조한다. )
emp.deptno <-> dept.deptno
join의 using(employee_id)처럼?
insert into dept(deptno, dname) values(10, '개발부');
insert into dept(deptno, dname) values(20, '영업부');
insert into dept(deptno, dname) values(30, '관리부');
insert into dept(dname) values(40, '경리부'); -- 입력하기 위해 지정한 row 보다 들어가는 값의 수가 더 많음.
-- → ORA-00913: 값의 수가 너무 많습니다
insert into dept(deptno, dname) values(40, '경리부');
insert into emp(empno, ename, deptno) values(100, '강호동', 10);
insert into emp(empno, ename, deptno) values(101, '아이유', 20);
insert into emp(empno, ename, deptno) values(102, '유재석', 50);
-- → 50번부서 없음(무결성제약조건위배)-부모키가 없습니다
insert into emp(empno, ename, deptno) values(103, '이효리', 40);
insert into emp(empno, ename) values(105, '장동건');
insert into emp(ename, deptno) values('고소영', 10);
-- → primary key는 NULL허용 안함
-- ORA-01400: NULL을 ("HR"."EMP"."EMPNO") 안에 삽입할 수 없습니다
-- hr.emp.empno는 primary key이기때문에 null을 넣을 수 없다,
commit;ex24) 삭제
delete from dept;
select * from dept;
rollback;
select * from dept;
delete from dept where deptno=40;
select * from dept;
select * from emp; -- null
ex25) 수정(update)
emp테이블 장동건 사원의 부서번호를 30으로 수정하시오
update emp set deptno=30 where ename='장동건';
select * from emp;
commit;
★ 7. VIEW
- 다른 테이블이나 뷰에 포함된 맞춤표현(virtual table)
join하는 테이블의 수가 늘어나거나 질의문이 길고 복잡해지면 작성이 어려워지고 유지보수가 어려울 수 있다.
이럴 때는 스크립트를 만들어두거나 stored query를 사용해서 데이터베이스 서버에 저장해두면 필요할 때 마다 호출해서 사용할 수 있다
- 뷰와 테이블의 차이는 뷰는 실제로 데이터를 저장하고 있지 않다는 점이다.
- 베이스테이블(Base table) : 뷰를 통해 보여지는 실제테이블
- 선택적인 정보만 제공 가능
[형식]
create [or replace][force|noforce] view 뷰이름 [(alias [,alias,.....)]
as 서브쿼리
[with check option [constraint 제약조건이름]]
[with read only [constraint 제약조건이름]]
- create or replace
: 지정한 이름의 뷰가 없으면 새로 생성, 동일이름이 있으면 수정
- force | noforce
force : 베이스테이블이 존재하는 경우에만 뷰 생성가능
noforce : 베이스테이블이 존재하지 않아도 뷰 생성가능
- alias
뷰에서 생성할 표현식 이름(테이블의 컬럼 이름의미)
생략하면 서브쿼리의 이름 적용
alias의 개수는 서브쿼리의 개수와 동일해야 함
- 서브쿼리 : 뷰에서 표현하는 데이터를 생성하는 select구문
- 제약조건
with check option
: where 조건에 사용된 컬럼 값은 뷰를 통해서는 변경이 불가능해진다.
만약 뷰를 생성할 때, 부서 번호가 20일 사원 정보만 추출했다면
해당 뷰로 부서 번호를 40번으로 변경할 수 없게 한다는 것이다.
부서 번호가 뷰를 생성할 때 조건으로 사용되었으므로, 절대 부서 번호 값은 뷰를 통해서는 변경할 수 없다!
with read only
: 뷰를 통해 DML작업 안됨
제약조건으로 간주되므로 별도의 이름지정가능
[뷰 - 인라인(inline)개념]
: 별칭을 사용하는 서브쿼리 (일반적으로 from절에서 사용)
[뷰 - Top N분석]
Top N분석 : 조건에 맞는 최상위(최하위) 레코드를 N개 식별해야 하는 경우에 사용
예) 최상위 소득자3명
최근 6개월동안 가장 많이 팔린 제품3가지
실적이 가장 좋은 영업사원 5명
오라클에서 Top N분석원리
- 원하는 순서대로 정렬
- rownum 이라는 가상의 컬럼을 이용하여 순서대로 순번부여
- 부여된 순번을 이용하여 필요한 수만큼 식별
- rownum값으로 특정행을 선택할수 없음
(단, Result Set 1st 행(rownum=1)은 선택가능)
ex1) 사원테이블에서 부서가 90인 사원들을 v_view1으로 뷰테이블을 만드시오
(사원ID, 사원이름, 급여, 부서ID만 추가)
create or replace view v_view1
as select employee_id, last_name, salary, department_id from employees
where department_id=90;
select * from v_view1;
delete from v_view1;- error
ORA-02292: integrity constraint (HR.DEPT_MGR_FK) violated - child record found
# 사원테이블에서 급여가 5000 이상 10000 이하인 사원들만 v_view2으로 뷰를 만드시오.
(사원ID, 사원이름, 급여, 부서ID)
create or replace view v_view2
as select employee_id as 사원ID, last_name as 사원이름, department_id as 부서ID, salary
from employees
--where salary >= 5000 and salary <= 10000;
where salary between 5000 and 10000;
select * from v_view2;ex2) v_view2 테이블에서 103사원의 급여를 9000.00에서 12000.00으로 수정하시오
select * from v_view2;
update v_view2 set salary=12000 where employee_id=103;
select * from v_view2; -- ← 103사원이 빠졌음(범위를 벗어남)
# 사원테이블과 부서테이블에서 사원번호, 사원명, 부서명을 v_view3로 뷰 테이블을 만드시오
조건1) 부서가 10, 90인 사원만 표시하시오
조건2) 타이틀은 사원번호, 사원명, 부서명으로 출력하시오
조건3) 사원번호로 오름차순 정렬하시오
create or replace view v_view3
as select employee_id, last_name, department_name
from employees
join departments using(department_id)
where department_id = 10 or department_id = 90
order by 1;
select * from v_view3;
# 부서ID가 10, 90번 부서인 모든 사원들의 부서위치를 표시하시오
조건1) v_view4로 뷰 테이블을 만드시오
조건2) 타이틀을 사원번호, 사원명, 급여, 입사일, 부서명, 부서위치(city)로 표시하시오
조건3) 사원번호 순으로 오름차순 정렬하시오
조건4) 급여는 백 단위 절삭하고, 3자리 마다 콤마와 '원'을 표시하시오
조건5) 입사일은 '2004년 10월 02일' 형식으로 표시하시오
create or replace view v_view4
as select employee_id 사원번호, last_name 이름, to_char(trunc(salary,-3),'999,999')||'원' 급여, to_char(hire_date,' YYYY"년" MM"월" DD"일" ') as 날짜, department_name 부서, city 위치
from employees
join departments using(department_id)
join locations using (location_id)
order by 1;
select * from v_view4;
ex3) 뷰에 제약조건달기
사원테이블에서 업무ID 'IT_PROG'인 사원들의 사원번호, 이름, 업무ID만 v_view5 뷰 테이블을 작성하시오.
단 수정 불가의 제약조건을 추가 하시오
create or replace view v_view5
as select employee_id, last_name, job_id
from employees
where job_id='IT_PROG'
with read only;
select * from v_view5;
delete from v_view5;
ex4) 뷰에 제약조건 달기
사원테이블에서 업무ID 'IT_PROG'인 사원들의 사원번호, 이름, 이메일, 입사일, 업무ID만 v_view6 뷰 테이블을 작성하시오,
단 업무ID가 'IT_PROG'인 사원들만 추가, 수정할 수 있는 제약조건을 추가하시오
create or replace view v_view6
as select employee_id, last_name, email, hire_date, job_id
from employees
where job_id='IT_PROG'
with check option;
-- IT_PROG만 수정 가능한 체크 옵션
select * from v_view6;
insert into v_view6(employee_id, last_name, email, hire_date, job_id)
values(500,'kim','candy','2004-01-01','Sales');
-- → 에러:with check option제약조건에 위배
update v_view6 set job_id='Sales' where employee_id=103;
-- → 에러:with check option제약조건에 위배
insert into v_view6(employee_id, last_name, email, hire_date, job_id)
values(500,'kim','candy','2004-01-01','IT_PROG');
select * from v_view6;
delete from v_view6;- error
ORA-02292: integrity constraint (HR.DEPT_MGR_FK) violated - child record found
# 책방 예제
-- 책방 테이블 생성
create table bookshop(
isbn varchar2(10) constraint PISBN primary key,
title varchar(50) constraint CTIT not null,
author varchar2(50),
price number,
company varchar2(30)
);
-- 시퀀스 생성
create sequence idx_seq increment by 1 start with 1 nocache nocycle;-- foreign key 방법 1
create table bookorder(
idx number primary key,
isbn varchar2(10) constraint FKISBN references bookshop(isbn),
qty number
);
-- foreign key 방법 2
create table bookorder(
idx number primary key,
isbn varchar2(10),
qty number,
constraint FKISBN foreign key(isbn) references bookshop
);
-- 주문 내역 넣기
insert into bookorder values (idx_seq.nextval, 'is001', 2);
insert into bookorder values (idx_seq.nextval, 'or003', 3);
insert into bookorder values (idx_seq.nextval, 'pa002', 5);
insert into bookorder values (idx_seq.nextval, 'is001', 3);
insert into bookorder values (idx_seq.nextval, 'or003', 10);-- 책방에 주문내역 join 걸어서 그룹 생성 출력 후 뷰 생성
create or replace view bs_view("책 제목", 저자, 총판매금액)
as select title, author, sum(qty*price)
from bookshop
join bookorder using(isbn)
group by title, author
with read only;group by 는 출력되는 모든 컬럼이 그룹식에 선언되어야 한다.
그룹 함수로 쓰이지 않은 컬럼은 , group by 뒤에 모두 입력되어야 한다.
ex5) 뷰 - 인라인
사원테이블을 가지고 부서별 평균급여를 뷰(v_view7)로 작성하시오
조건1) 반올림해서 100단위까지 구하시오
조건2) 타이틀은 부서ID, 부서평균
조건3) 부서별로 오름차순 정렬 하시오
조건4) 부서ID가 없는 경우 5000으로 표시하시오
-- 1. 뷰 테이블
create or replace view v_view7("부서ID", "부서평균")
as select nvl(department_id, 5000),
round( avg(salary), -3)
from employees
group by department_id
order by department_id asc;
select * from v_view7;
----------------------------------------
-- 2. 인라인 방식
select 부서ID, 부서평균
from (select nvl(department_id, 5000) "부서ID",
round( avg(salary), -3) "부서평균"
from employees
group by department_id
order by department_id asc);
[문제5] 1. 부서별 최대급여를 받는 사원의 부서명, 최대급여를 출력하시오
2. 1번 문제에 최대급여를 받는 사원의 이름도 구하시오

-- 1.
select department_name, max(salary)
from employees
join departments using(department_id)
group by department_name;
-- 인라인 방식
select 부서명, 최대급여
from (select department_name as 부서명, max(salary) as 최대급여
from employees
join departments using(department_id)
group by department_name);-- 2.
select 이름, 부서명, 최대급여
from (select last_name as 이름,
department_name as 부서명,
salary as 최대급여
from employees
join departments using(department_id)
where(department_id, salary) in (select department_id, max(salary) from employees group by department_id));
ex6) Top N분석
급여를 가장 많이 받는 사원3명의 이름, 급여를 표시 하시오
select rownum, last_name, salary
from (select last_name, nvl(salary,0) as salary from employees order by 2 desc)
where rownum <= 3;
ex7) 최고급여를 받는 사원1명을 구하시오
select rownum, last_name, salary
from (select last_name, nvl(salary,0)as salary from employees order by 2 desc)
where rownum=1; --← rownum=2는 error (특정 행은 사용할 수 없음)
ex8) 급여의 순위를 내림차순 정렬 했을 때, 3개씩 묶어서 2번째 그룹을 출력하시오
(4,5,6 순위의 사원 출력 : 페이징 처리 기법)
-- ceil 사용
select * from
(select rownum , ceil(rownum/3) as page, tt.* from -- ceil은 올림. 0.333 -> 1
(select last_name, nvl(salary,0)as salary from employees order by salary desc)tt --> tt라고 명명
) where page=2;
--1 ~ 9번 글 3개씩 페이지 나누기
-- ceil(1~ 3 /3) = 1
-- ceil(4~ 6 /3) = 2
-- ceil(7~ 9 /3) = 3
-- 범위 지정
select * from
(select rownum rn, tt.* from
(select last_name, nvl(salary,0) as salary from employees order by 2 desc)tt
) where rn>=4 and rn<=6;
[문제6] 사원들의 연봉을 구한 후 최하위 연봉자 5명을 추출하시오
조건1) 연봉 = 급여*12+(급여*12*커미션)
조건2) 타이틀은 사원이름, 부서명, 연봉
조건3) 연봉은 ₩25,000 형식으로 하시오
select * from
(select rownum rn, ceil(rownum/5) as page, pp.*
from (select last_name, department_name, to_char(salary * 12 + (salary * 12 * commission_pct),'L999,999') as annual
from employees
join departments using(department_id)
order by 3 asc)pp)
where page = 1;
★ 8. SYNONYM
- Synonym은 오라클 객체(테이블, 뷰, 시퀀스, 프로시저)에 대한 대체이름(Alias)를 말한다
- Synonym은 Object가 아니라 Object에 대한 직접적인 참조이다
- 데이터베이스의 투명성을 제공하기 위해서 사용 한다
다른 유저의 객체를 참조할 때 많이 사용 한다
- 객체의 긴 이름을 짧게 만들어 SQL 코딩을 단순화 할 수 있다
- 객체의 실제 이름, 소유자, 위치를 감추기 때문에 데이터베이스의 보안을 유지할 수 있다
* 종류
Private Synonym
전용 Synonym은 특정 사용자만 사용할 수 있다
Public Synonym
공용 Synonym은 사용자 그룹이 소유하면 그 데이터베이스에 있는 모든 사용자가 공유한다
[형식]
CREATE [PUBLIC] SYNONYM 시노님이름 FOR 객체이름
[실습]
1. HR 계정으로 접속해서 C##JAVA 계정에게 EMPLOYEES 테이블을 조작할 수 있는 권한 부여
-- 현재위치 : hr
grant all on employees to c##java;2. JAVA 계정에 접속해서 Synonym(동의어)를 생성
hr계정의 employees 테이블을 java계정에서 hr_emp 동의어로 사용한다
CREATE SYNONYM Synonym이름 FOR 다른 계정의 테이블명
-- 현재위치 : c##java
create synonym hr_emp for hr.employees;ORA-01031: 권한이 불충분합니다
01031. 00000 - "insufficient privileges"
*Cause: An attempt was made to perform a database operation without
the necessary privileges.
*Action: Ask your database administrator or designated security
administrator to grant you the necessary privileges
★ 먼저 SYNONYM를 생성할 수 있는 권한이 있어야 한다
SYSTEM 계정에서 권한을 부여한다
-- 현재위치 : SYSTEM
grant create synonym to c##java;다시 c##java 계정에서
--현재위치 : c##java
create synonym hr_emp for hr.employees; -- "계정.테이블" 주소로 적는 방법
select * from user_synonyms;
3. 쿼리
select * from hr.employees;
이런 식으로 사용하면 SQL문이 길어질 때 테이블명이 길어서 문제가 되고 다른 스키마(계정)에 있는 객체의 위치를 알려주게 되어 보안상 안 좋다
select * from hr_emp; - Synonym 이용
Synonym 이름을 짧게 하여 SQL문 길이도 줄이고 보안유지도 되기 때문에 사용 한다
select * from hr_emp; -- [실습 - 2.]에서 지정한 Synonym명으로 호출
4. 삭제
DROP SYNONYM 시노님명
drop synonym hr_emp;
select * from user_synonyms;Synonym 동의어가 삭제된 것을 확인할 수 있다
'Dev > SQL' 카테고리의 다른 글
| [ Oracle 18c ] SYSTEM 계정 비밀번호를 잊어버렸을때 (0) | 2021.03.21 |
|---|